In the realm of artificial intelligence (AI) and machine learning (ML), data annotation plays a vital role in training models to recognize patterns, understand relationships, and derive meaningful insights from raw data. Data annotation involves the process of labeling or tagging data with relevant information to make it understandable for AI algorithms.
In this comprehensive guide, we’ll delve into the various data annotation techniques, with a focus on image annotation, video annotation, text annotation, audio transcription, and annotation.
Image Annotation
Image annotation is a fundamental technique used in computer vision applications to label objects, shapes, or regions within images. There are several image annotation techniques, including:
Bounding Box Annotation
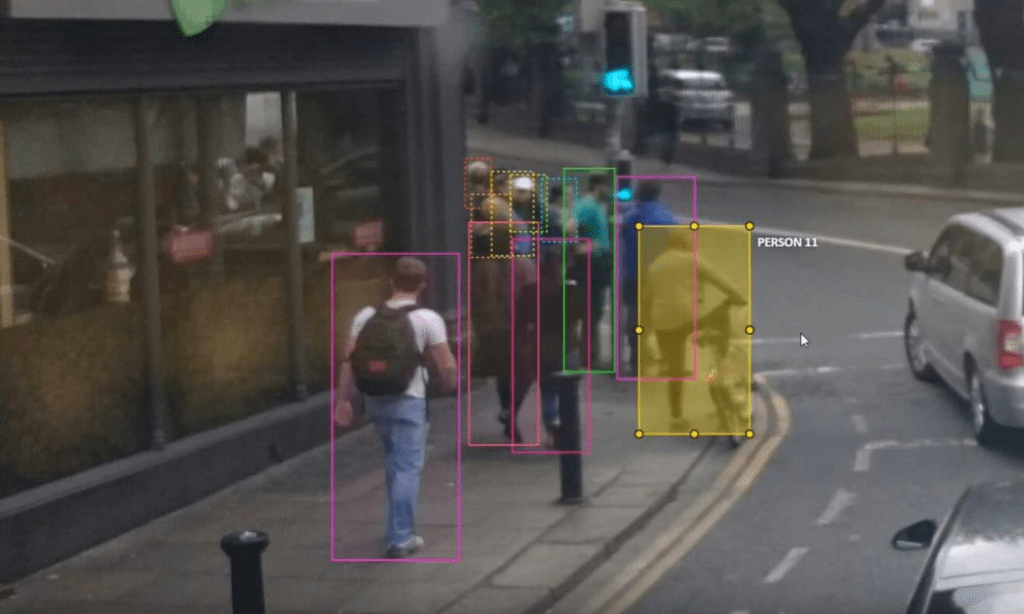
Bounding box annotation involves drawing rectangular boxes around objects of interest within images. This technique is commonly used for object detection tasks, where the goal is to localize and identify objects within images accurately.
Polygon Annotation
Polygon annotation involves outlining objects with polygonal shapes to provide more precise boundaries. This technique is useful for annotating irregularly shaped objects or regions within images, such as vehicles, buildings, or natural landscapes.
Semantic Segmentation
Semantic segmentation is a pixel-level annotation technique that categorizes each pixel within an image into predefined classes or categories. This technique provides detailed information about the semantic content of the image and is widely used in applications such as image segmentation, scene understanding, and object recognition.
Video Annotation
Video annotation extends the principles of image annotation to the temporal domain, where objects, actions, or events within videos are labeled and annotated. Common video annotation techniques include:
Object Tracking
Object tracking involves annotating objects across consecutive frames of a video to track their movement and trajectory over time. This technique is essential for applications such as surveillance, activity recognition, and sports analytics.
Action Recognition
Action recognition involves annotating specific actions or activities performed by individuals or objects within videos. This technique enables AI models to understand and classify human actions, gestures, and behaviors accurately.
Temporal Segmentation
Temporal segmentation involves dividing a video into segments or intervals based on changes in content, context, or activity. This technique helps in organizing and structuring video data for tasks such as video summarization, content-based retrieval, and event detection.
Text Annotation
Text annotation involves labeling or tagging textual data with relevant information to facilitate natural language processing (NLP) tasks. There are several text annotation techniques, including:
Named Entity Recognition (NER)
Named Entity Recognition (NER) involves identifying and annotating named entities such as persons, organizations, locations, dates, and numerical values within text. This technique is essential for tasks such as information extraction, document categorization, and entity linking.
Sentiment Analysis
Sentiment analysis involves annotating text with sentiment labels such as positive, negative, or neutral to analyze the emotional tone or sentiment conveyed in the text. This technique is widely used in applications such as social media monitoring, customer feedback analysis, and opinion mining.
Text Classification
Text classification involves categorizing text documents or sentences into predefined classes or categories based on their content or topic. This technique enables AI models to organize, filter, and analyze textual data effectively for tasks such as topic modeling, spam detection, and content recommendation.
Audio Transcription and Annotation
Audio transcription involves converting spoken words or audio signals into written text, followed by annotation to extract meaningful information. Common audio annotation techniques include:
Speech-to-Text Transcription
Speech-to-text transcription involves converting spoken words or audio signals into written text using automatic speech recognition (ASR) technologies. This technique enables AI models to transcribe audio data accurately and efficiently for tasks such as voice search, virtual assistants, and speech analytics.
Speaker Diarization
Speaker diarization involves annotating audio segments with speaker identities to distinguish between different speakers in a conversation or audio recording. This technique is essential for tasks such as speaker identification, speaker verification, and voice biometrics.
Sound Event Detection
Sound event detection involves annotating audio segments with labels corresponding to specific sound events or environmental sounds. This technique enables AI models to recognize and classify sound events such as alarms, sirens, footsteps, and animal calls in audio recordings.
Conclusion
In conclusion, data annotation is a crucial step in the development of AI and ML models, enabling them to understand and interpret raw data effectively. Image annotation, video annotation, text annotation, and audio transcription and annotation are essential techniques that provide valuable context and semantics to diverse types of data, ranging from images and videos to text and audio. By leveraging these annotation techniques, organizations can unlock the full potential of AI-driven solutions across various domains and applications.

Leave a comment